前言
好久没动笔写博客了,为了不给2017留空白,特写此篇。 这篇文章提到的案例、方法、方案有些是在之前的文章中会零散提到过,都是在公司内部分享多次以及迭代多次的结果,当然,敏感数据的地方我会换成一些fake的数据,注重方法论,数据上有问题的地方请包容。
这个话题其实可以涉及到各种各样的场景,我这里仅仅是把我们公司内部经常遇到的一些问题拉出来分享。本文的案例基本上都基于linux环境的java程序进行分析,如果你是windows或者其他的操作系统,可能有些工具需要自己寻找、下载。
首先讲讲排查思路
1. 出现问题之前,是否刚刚做了发布(上线新的代码:功能、修改等)
- 是:结合内部的服务器监控系统(zabbix等)的数据,判断是否在发布的时间节点前后发生不一样的现象,如果是,基本可以断定是新代码导致的问题,第一时间回滚代码(如果可以的话,技术方案设计上本来也要考虑失败回滚的问题),先恢复应用的正常访问(服务),再分析新上的代码是否有问题。
- 否:如果是历史遗留的问题,就需要结合工具来排查(这写就是本文会讲解的重点)
2. 关于日志
- 日志不是越详细越好,记录关键信息才是真理。如果每次打印日志都把过程数据写上,反而容易引起磁盘io问题、内存频繁ygc问题。
- 日志要有意义,debug性质的日志一律用 debug级别,线上禁止打印 debug级别的日志。
- 区分性能日志和业务日志:性能日志用于发现性能问题,业务日志用于记录业务流水方便后期追溯。
排查工具
- ps | grep 组合命令, 方便快速找到进程id(java有自带的jps工具)
- vi/tail/head/more/less: 查看线上日志的工具,注意不要用vim打开打日志,往往会给(内存)负担过重的服务器致命一击
- awk 文本分析脚本,可以快速分析性能、业务日志,得出结果,不用等大数据平台一系列流程
- top:查看进程(和线程)的cpu耗时,内存占用情况
- iotop:查看进程和线程的IO消耗情况 (需要自行安装)
- iftop:查看进程和线程的网络情况 (需要自行安装)
- lsof:查看文件打开情况(含网络、本地文件、设备等)
- JVM系列tools (本文重点)
- 8.1 jstat:查看进程内存分配和gc情况
- 8.2 jstack:查看进程的线程栈
- 8.3 jmap:dump java 内存。(不要对在线提供服务的应用做jmap)
- 8.4 btrace:运行中的代码调试
- 8.5 jprofile: 外挂的形式,分析具体到方法级别的相应耗时,压测配合jprofile,能直接找到瓶颈
- IBM Memory Analyzer Tool, 简称MAT,用于分析 jmap 命令dump出来的内存文件
- 监控工具
- 10.1 zabbix:观察系统的历史性能状态(顺便告警)
- 10.2 ganglia:观察系统的历史性能状态
- 10.3 vision: 我司内部自研系统,观察业务的性能数据,QPS vs RT
- 10.4 各式APM工具,比如OneAPM,听云等,通过javaagent的方式实时分析程序的性能问题
一些案例
案例1. 进程耗CPU咋办
一般两种问题:
– a. 业务代码中有大(或死)循环,消耗大量CPU计算资源
– b. 垃圾回收(GC)频繁,导致gc线程消耗大量CPU (FullGC、YoungGC均会消耗CPU资源)
针对a情况,如何找到消耗CPU的代码段?
- ps | grep 组合键找到进程id
- top -H -p $pid 列出线程详情 (-H命令可以显示线程情况)
- 找到耗CPU最高的几个线程ID ( 同时按下 shift + T , 按CPU时间(Time)排序) ,在-H模式下,pid就是线程id
- printf %x $tid 把线程ID转化为16进制, 记录下来
- jstack -l $pid ,dump出线程栈 ,最好写到文件里
- 通过第四步得到的线程ID的16进制,在线程栈里面找到相应的线程栈信息 (nid=0x16进制线程ID)
至此,定位到的代码段一般就是耗CPU的代码段了。
通过上述排查,如果耗CPU的线程是VM Thread,说明是进入了b情况
- 首先,我们必须清楚gc的情况,如果没有开启gc日志,只能通过 jstat命令查看
- jstat -gc $pid , 观察 YoungGCCount 和 FullGCCount 的增速
- 如果ygc快速增加,说明是新生代内存分配和回收过快 (比如每秒增加几十次ygc),此时需要结合观察日志,看某种业务(服务)是否在快速打日志,是的话一般就是此处的频繁工作引起问题。
- 如果fgc快速增加,说明是老生代的内存一直不够用(晋升失败),此时可以通过jmap 命令dump内存,到本地用mat工具分析
案例2. 进程or线程hang住了怎么办
一般原因
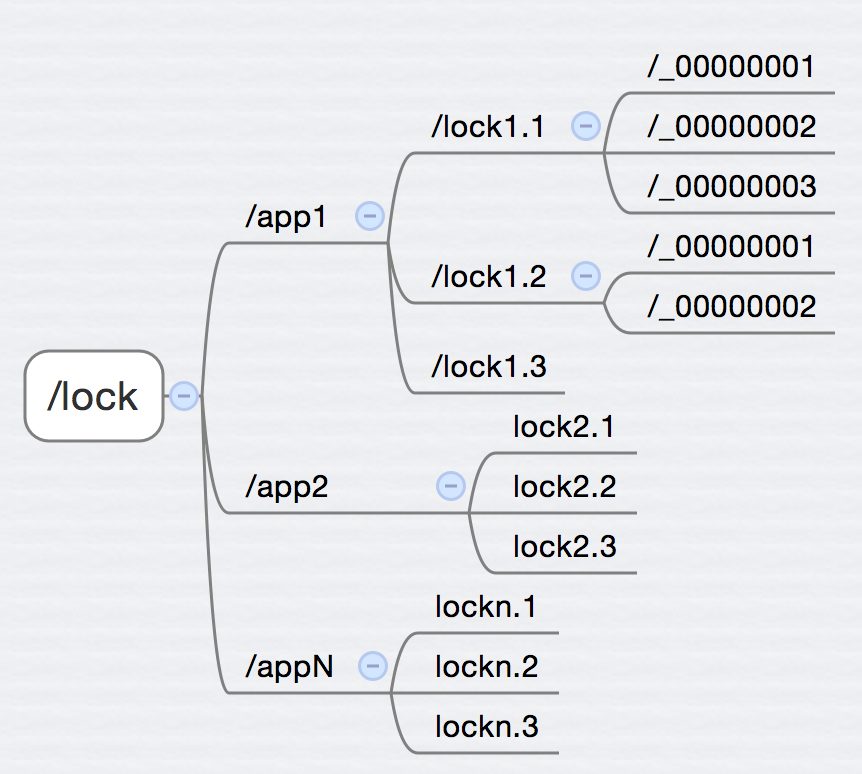
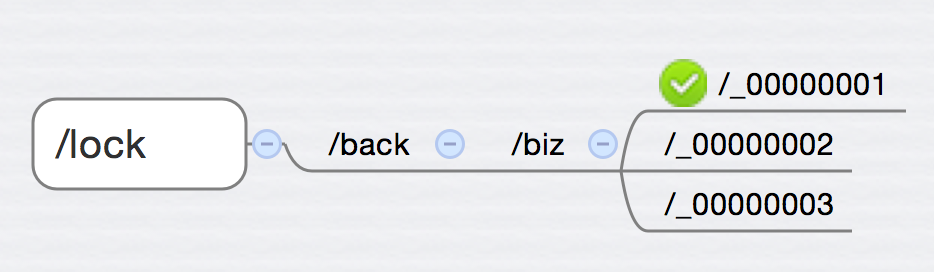
- 死锁(本地锁&分布式锁)
- 依赖的远程服务hang住&没有设置超时时间
- 线程池耗尽 or 连接池耗尽
- 死循环
- 调用网络服务,但网卡带宽被耗尽
解决方法
- 排查是否死锁
- 设置远程服务(含API、MQ消息、分布式锁等)的超时时间,业务需要兼容
- 调高线程池or连接池 & 缩短超时时间(业务需要做兼容)
排查死锁的方法
很简单,通过jstack工具,他会直接告诉你死锁在哪。
1. 找出进程ID
2. jstack -l dump出线程栈
3. 通过 deadlock 关键字找到相关线程信息即可
案例3. 进程周期性卡顿怎么办
一般原因
- 有定时任务,定时任务触发时把系统拖慢
- 有定时fullgc,可能是定时任务导致的fullgc,也可能是定时触发fullgc。fullgc时会stop the world。
解决方法
- 如果是定时任务,优化定时任务对内存的使用
- 如果是定时触发fullgc,而系统不能接受,则配置vm参数禁用fullgc
排查过程
- 启动参数中要添加gc日志
- 如果没有gc日志,则通过jstat -gc 命令来查看gc情况
- 如果OU(old区使用量)远远没有达到OC(old区容量)就触发了fullgc,一般是定时触发,可以通过添加 -XX:+DisableExplicitGC 参数禁用定时触发的fullgc。
案例4. 进程OOM怎么办
首先,要先知道有哪些OOM,每种OOM都是有什么问题引起的。
OOM种类
- gc overhead limit exceeded :jvm花大量时间回收少量的内存。
- java heap space:heap内存不够用,无法继续分配内存,且无法回收足够的内存
- heap的大小由 -Xms 和 -Xmx 决定
- 一般配置了 -XX:-UseGCOverheadLimit 就不会出现gc overhead limit exceeded 问题, 最终会变成 java heap space
- unable to create new native thread:超过资源限制
- 进程、线程数超过了系统限制(ulimit)
- 线程数超过了kernel.pid_max的限制
- perm gen space: 持久代不够用
- 持久代不够用,调大 PermSize 参数
- 调大也没用?怀疑classloader错误使用。
- direct buffer memory :堆外内存使用超出限制的大小
- 如果机器内存足够大,可以调大 -XX:MaxDirectMemorySize 参数
- 一般是网络通信没有限流,而且用内存做buffer
- 定时fgc 主动回收堆外内存
- map failed: FileChannel map的文件超过了限制
- 调大 vm.max_map_count 系统参数可解
- Requested array size exceeds VM limit: 创建数组大小超过jvm限制
- 创建Integer.MAX_VALUE – n 以上长度的数组会抛出, n和jvm实现、系统环境有关
- request ? bytes form ?. Out of swap space
- 地址空间不够用(一般32bit系统才会碰到),物理内存耗光
- 强制触发fullgc看有没有好转,有的话可能是DirectByteBuffer误用造成的
- jmap -histo:live $pid 可以强制触发fullgc。
排查过程
- 先把服务摘离线上服务集群
- dump服务的内存,由于OOM后java进场可能会无法直接访问,需要使用jmap的-F参数强制dump
- 将dump出来的文件拉到本地环境,用mat工具分析。
参考链接
- 阿里研究员 毕玄 的博客:http://bluedavy.me/
- 官方troubleshooting文档:http://dwz.cn/javatsg
- OOM shooting: https://plumbr.io/outofmemoryerror