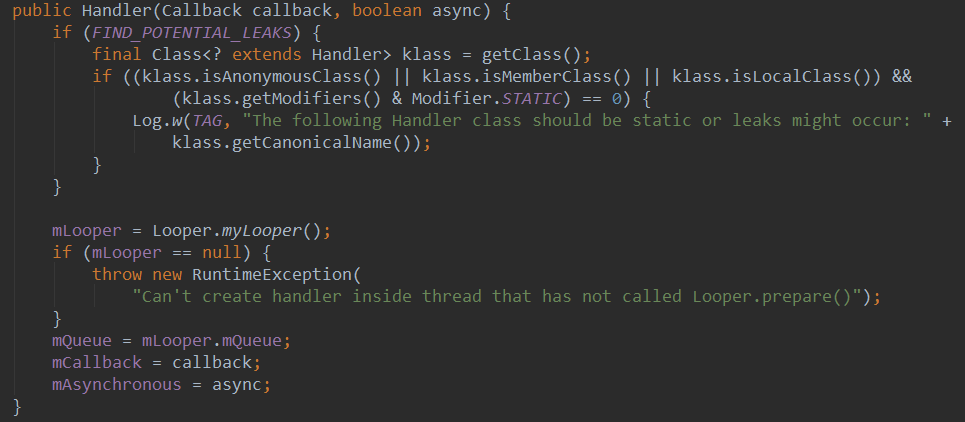
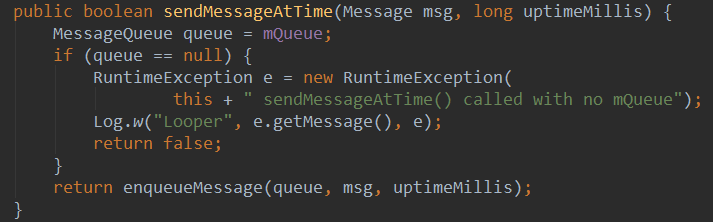
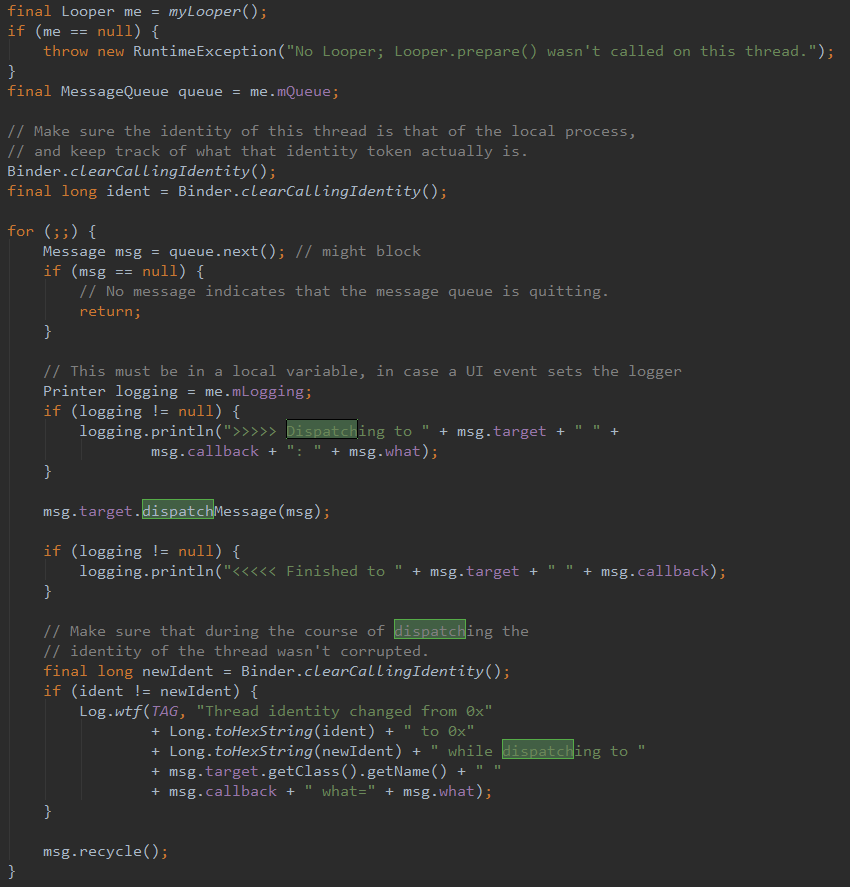
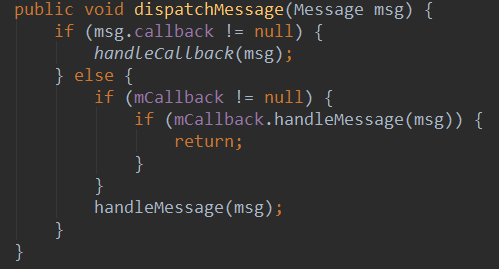
前面的文章已经分析了Handler和AsyncTask的原理,现在说说他们的异同点:
1. 相同点:AsyncTask就是封装了Thread+Handler,来简单实现做异步任务同时又能更新UI
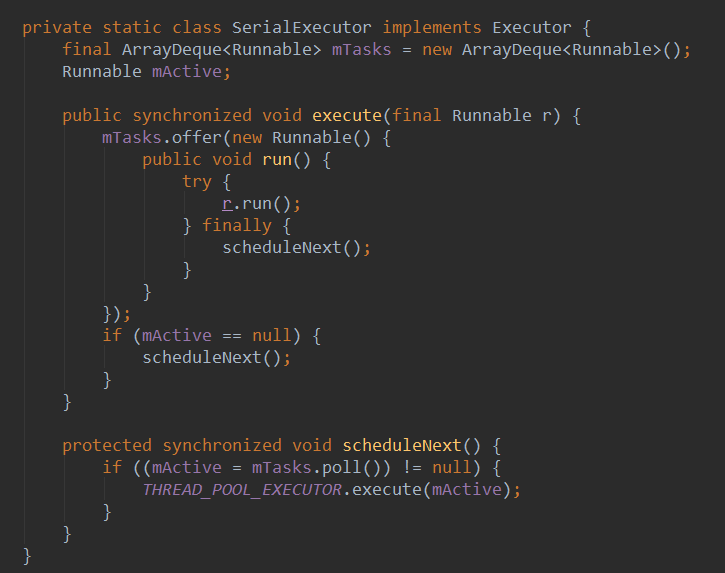
2. 不同点: 在android 3.0之后的AsyncTask中的任务默认是串行执行的,如果你有多个异步任务要并发执行,应该使用Thread(Pool)来替代。 当然AsyncTask也是考虑到了这一点,所以提供了一个executeOnExcutor方法,可以传入我们自定义的executor来进行并发执行。AsyncTask内部实现的Executor是SerialExecutor, 是串行执行的,来看代码他是如何串行化的: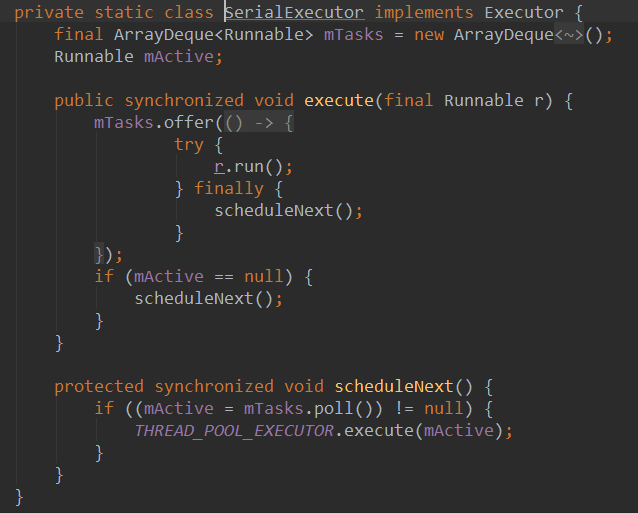
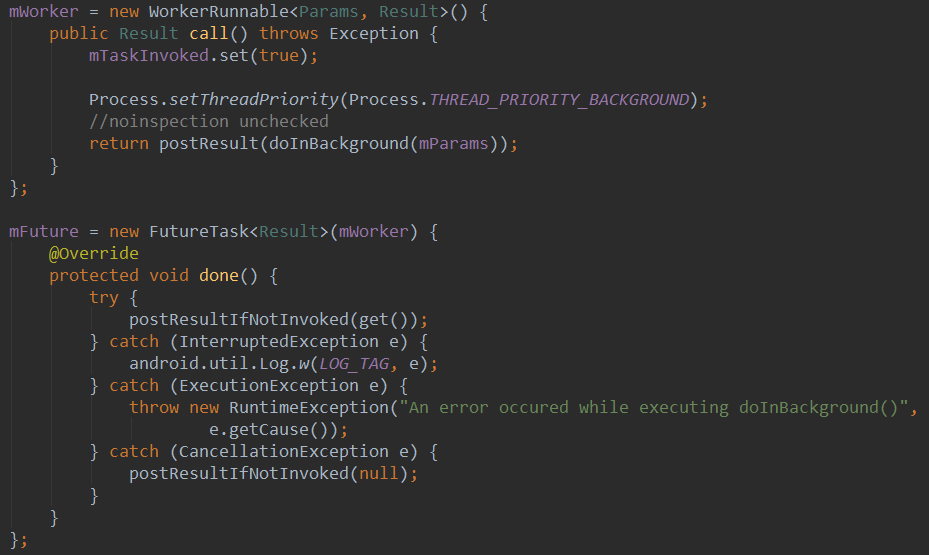
调用execute的时候,会先把异步任务封装为一个runnable放到一个队列里面,然后再判断要不要执行该任务。
判断的依据很简单,如果当前已经有任务在跑了,那么就不跑了。那么,这个任务会被丢弃吗?不会!当前任务执行后的finally块里面会执行下一个任务。这里的mActive变量设计的很巧妙,当mTasks.poll()得到的下一个任务为空的时候, 就不会再往下执行了, 所以可以保证所有任务都能被执行到,而且任务都是串行执行的。这里execute和scheduleNext两个方法都加上了synchronized关键字,所以也不会有线程安全的问题。
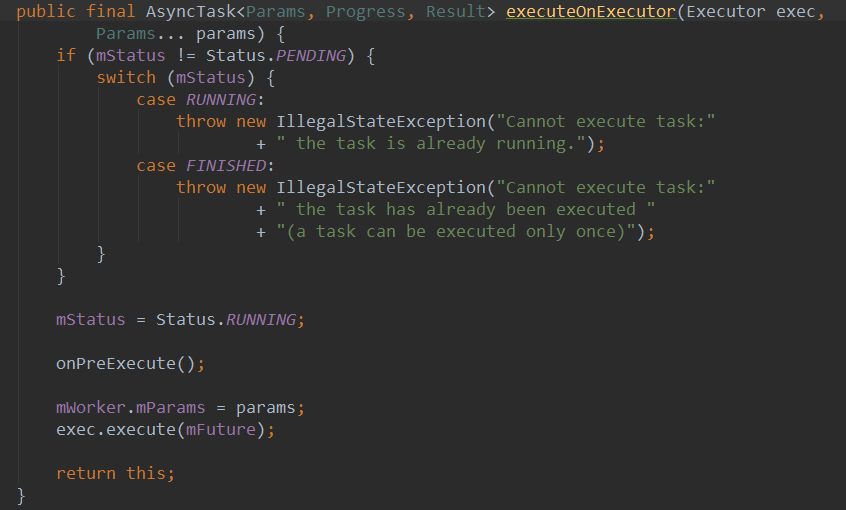
看下AsyncTask的execute方法:

这里用的是默认的Executor, 而这个默认的Executor就是SerialExecutor, 而且是单例的
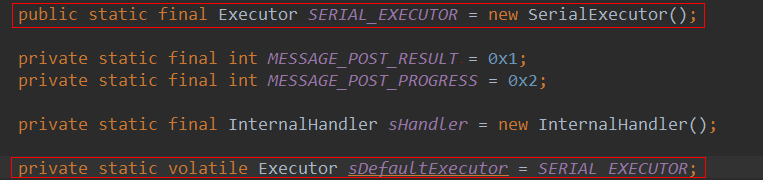
看到sDefaultExecutor前面有个volatile关键字就说明了这个Executor是可以被更改的,果不其然, AsyncTask提供了这么一个方法:

这样一来,我们通过更改默认的Executor就能达到AsyncTask里面的任务并发执行的目的。
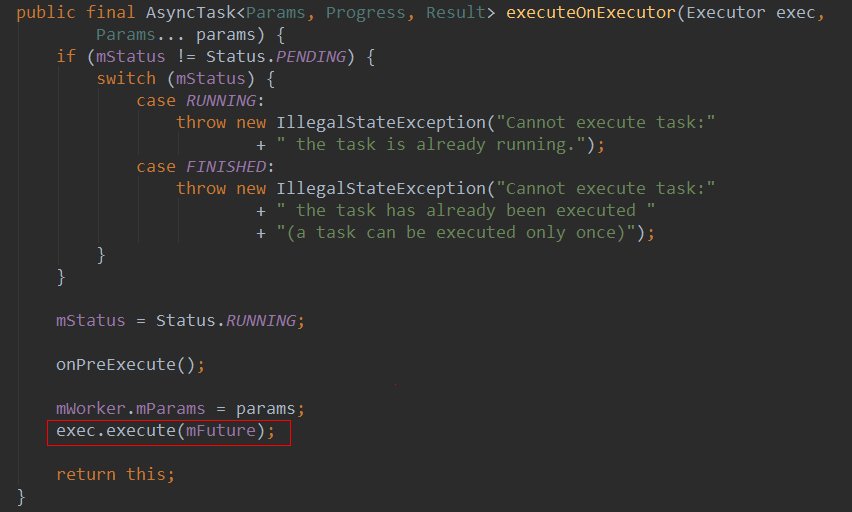
另外,回到AsyncTask的execute方法,是通过executeOnExecutor来提交任务的,而恰巧,executeOnExecutor这个方法是public的,说明我们也可以通过executeOnExecutor这个方法来指定我们自定义的Executor来执行任务,从而达到并发执行的目的。
同时,AsyncTask也定义了一个Executor常量供我们使用(实际上他的SerialExecutor也在用),就是
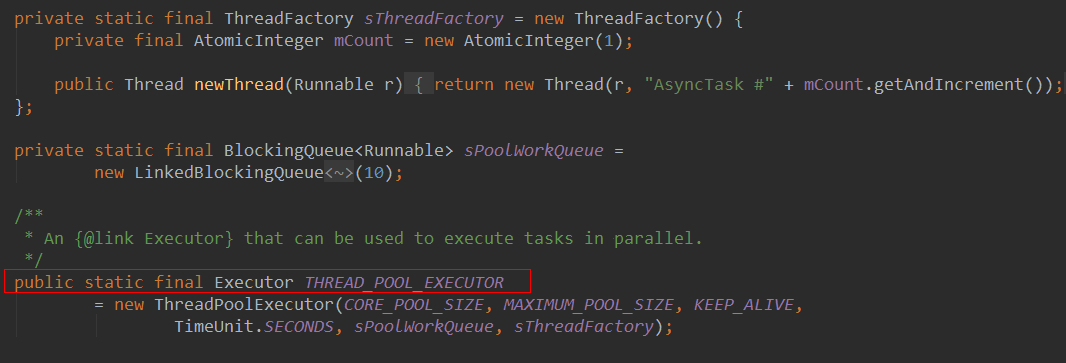
所以我们调用AsyncTask.executeOnExecutor的时候,可以把AsyncTask.THREAD_POOL_EXECUTOR作为第一个参数传过去即可,也省去了我们自己定义(如果实在需要还是真的要自己定义)的代码了。
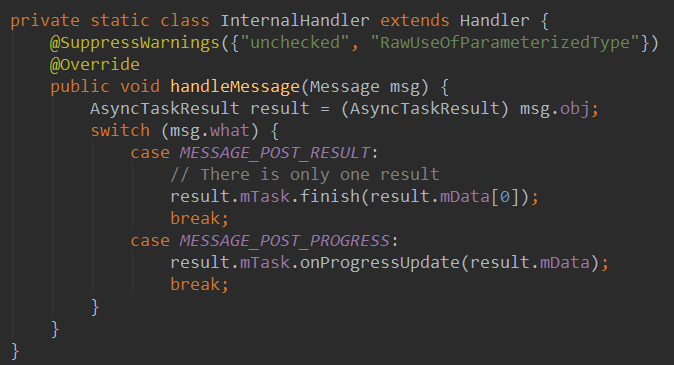
如果用Thread+Handler来实现类似AsyncTask类似的功能,可以用Handler的post方法,在Thread中处理任务的过程中,如果想要更新UI线程,有几种方法,一种是post,一种是sendMessage。如果从用法上来看,post应该说更实用一点,sendMessage的话你还要去封装一个消息,然后接受到消息的时候还要再把数据拿出来,进行UI的更新,例如:

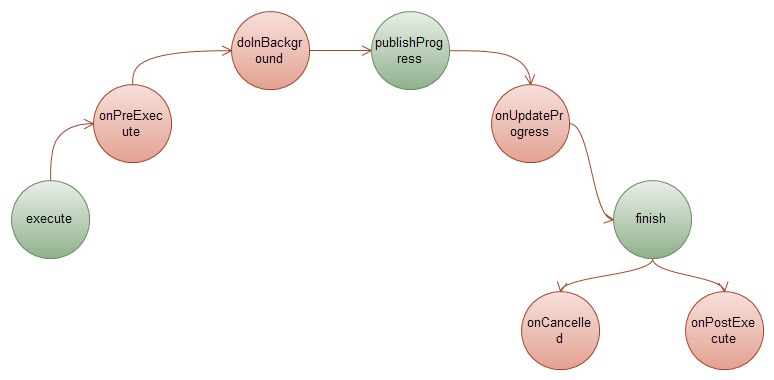
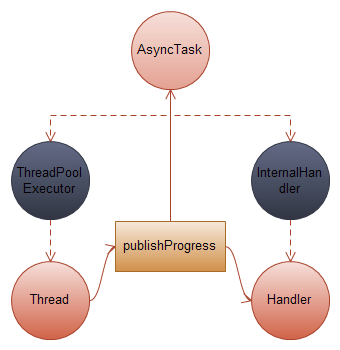
3. 最后画一幅图来总结一下AsyncTask和Handler之间的关系:
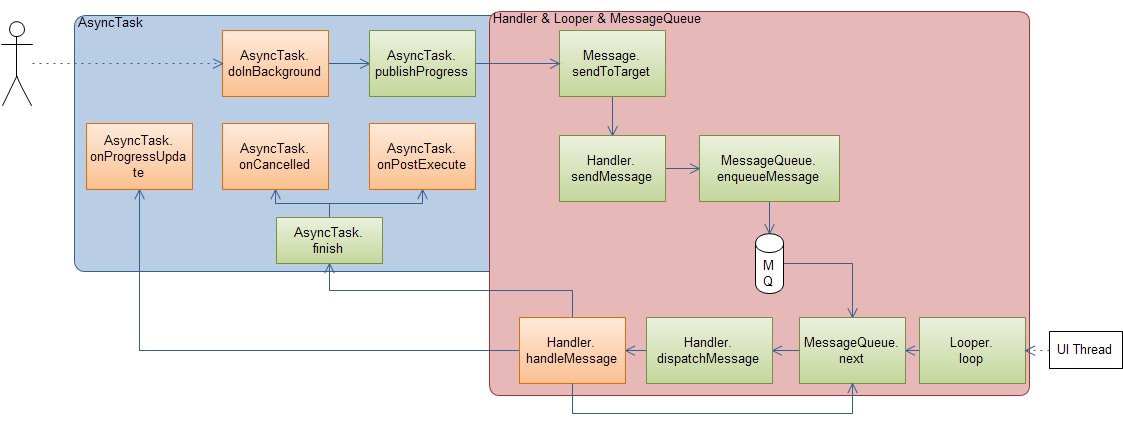
绿色部分是Android框架定义的方法,我们无需去重载,而粉色部分的方法我们可以去重载来实现自己的业务逻辑。
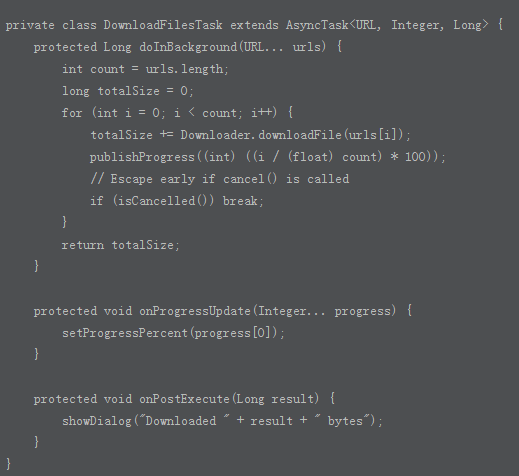
注意:在doInBackground被调用之前会有一个线程池的调度过程,以及会先执行onPreExecute这个方法,这里省略了。